这篇博客结合结合GPU基本架构与Shader的基本变量、调用方法,浅析了Shader是如何在GPU上运行的。帮助自己理解Shader执行时较为底层的机制,由于资历尚浅,文中或许存还在一些错误。
这篇博客参考了许多优秀的文章:
DX12渲染器开发(2):GPU硬件架构介绍 - 知乎 (zhihu.com)
OpenGL学习随笔(一)-- CPU和GPU的设计区别 - 幼儿园大班班长 - 博客园 (cnblogs.com)
1.1 CUDA编程模型之线程分配 - 简书 (jianshu.com)
(99+ 封私信 / 80 条消息) CUDA为什么要分线程块和线程网格? - 知乎 (zhihu.com)
SIMD数据并行(三)——图形处理单元(GPU) - 信号君 - 博客园 (cnblogs.com)
本文中组织结构如下:
- GPU概述
- GPU物理架构
- GPU渲染流程
- Computer Shader与GPU架构的对应关系
GPU概述
GPU全称是Graphics Processing Unit,中文称图形处理单元。最初是专门用于绘制图像和处理图元数据的特定芯片,后来渐渐加入了其它功能。
严格来说,GPU与显卡不应混淆。GPU是显卡(Video card、Display card、Graphics card)最核心的部件,但除了GPU,显卡还有扇热器、通讯元件、与主板和显示器连接的各类插槽。
GPU物理架构
GPU的结构因不同厂商、不同架构都会有所差异,但核心部件、概念、以及运行机制大同小异。这里以NVidia Turing架构为例,浅析GPU的物理架构。

针对上图,我们对涉及到的名词做概念上的解释和补充。并按照结构层级进行排布。
GPC:Graphics Processing Cluster,图形处理簇。
TPC:Texture/Processor Cluster,纹理处理簇:
SM:Stream Multiprocessor,流多处理器,也可简写为SMX、SMM。
SP:Streaming Processor,流处理器。等同于Core。 NVIDIA 称Core为CUDA Cores,AMD称 Core为Stream 。Processors。CUDA Cores vs Stream Processors Explained (graphicscardhub.com)
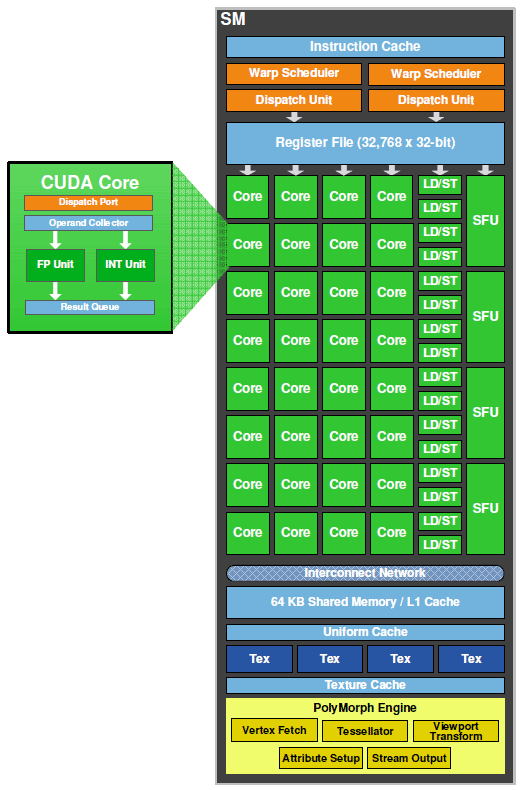
ALU(Arithmetic logic unit,即算术逻辑单元)是Core的组成部分。硬件实现过程中,为了尽可能提高其硬件性能ALU会按照其计算数据类型一般分为 Special Function Unit(SFU)、Integer Function Unit(INT 32 整型计算单元)、Float Point Unit(浮点型计算单元)。每个CUDA核均由单个FP32、单个INT32组成。 见图片“SM的内部构造示例”。
- FPU:Floating Point Unit
- Integer Function Unit
SFU:Special Function Unit,特殊函数单元。执行一些cos、log等运算,一个SM中少量SFU足矣。
Load/Store Unit:每次可以同时为Block内的16个线程计算目标地址和源地址,加快访存速度。有时简写为LD/ST Unit。
Warp Scheduler:Wrap称为线程束。一个Warp中包含32个线程,这些线程行任务时,执行相同的指令,但是数据不同,即“单指令多线程”,简称SIMT。一些SM里面就专设了32个SP(或Core),每个SP可以运行一个线程,一个warp中的32个线程个刚好可以跑在32个core上。往往将一个SM中的线程数设置为32*n,那么这n组之间就时间片轮转来使用SP。Wrap Scheduler切换Wrap执行。
Instruction Dispatch Unit:指令调度单元,从指令缓存中取出shader中的操作指令,分配给每个Core去执行。
Register File
L1 Cache
L2 Cache
Memory
Thread:线程。
ROP:Render Output Unit,渲染输出单元。
GPU渲染流程
本节总结了Fermi架构的运行机制,结合图形渲染流水线分析了一些步骤所涉及到的硬件结构。这部分需要对图形渲染流水线有一定的了解,可以看看龚大的视频上帝视角看GPU(1):图形流水线基础_哔哩哔哩_bilibili。
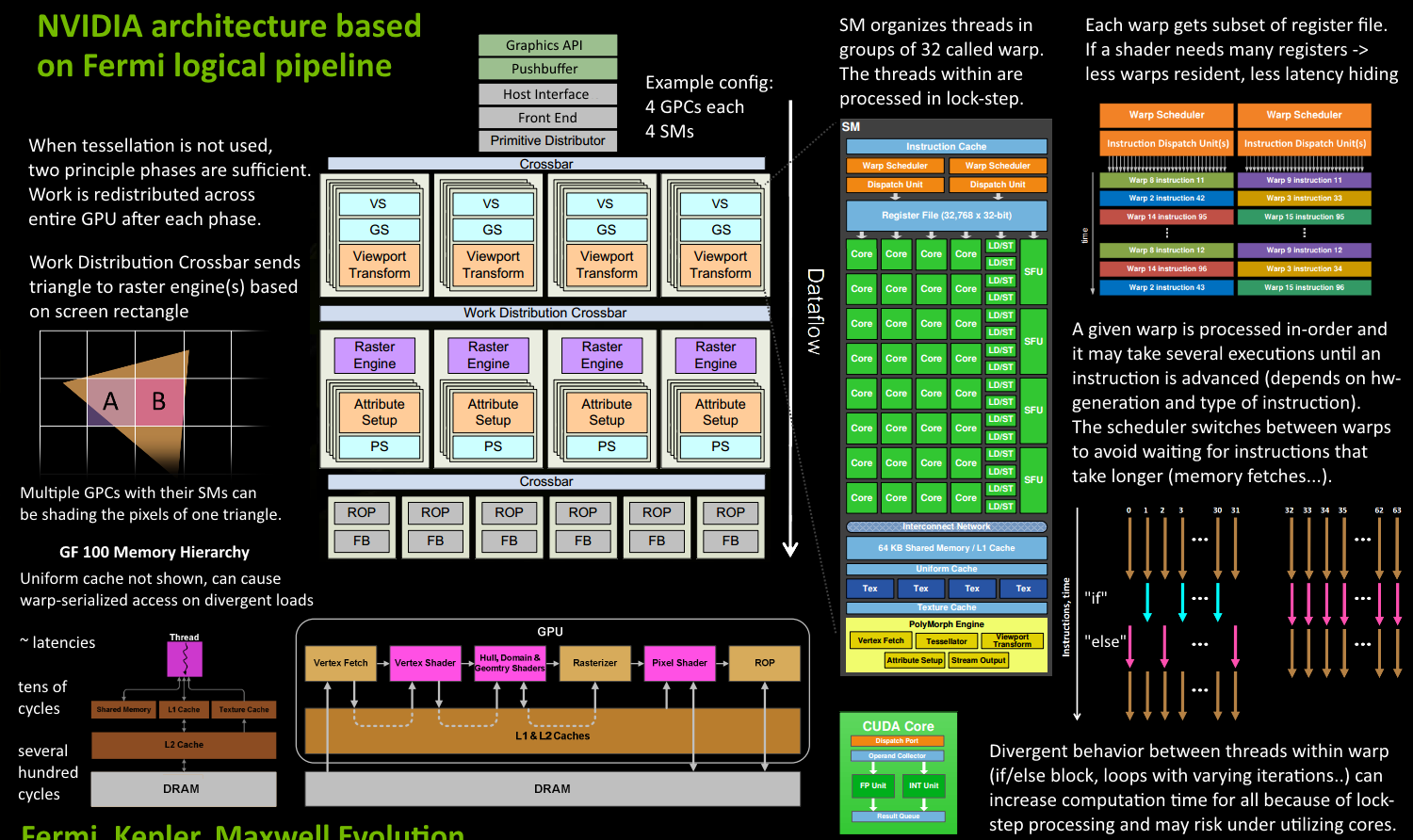
这张图片详细的阐述了GPU渲染的流程,但是我认为这张图的三个部分比较重要,下面称之为(A)、(B)和(C)。(A)和(B)之间其实是有关联的,在”GPU与图形渲染流水线“这张完整的图片中有两条虚线连接了(A)和(B)。
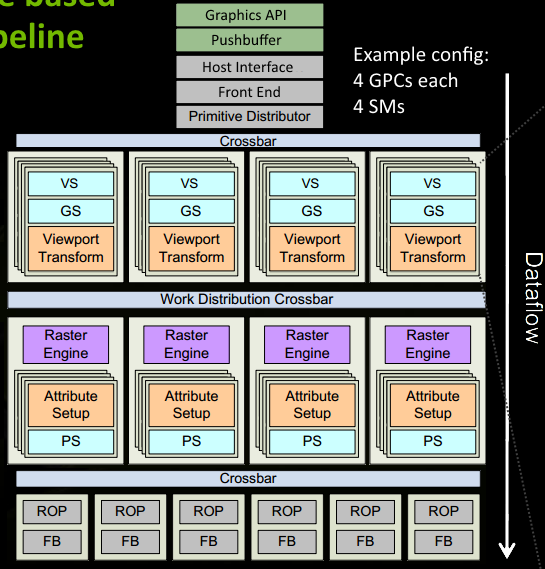

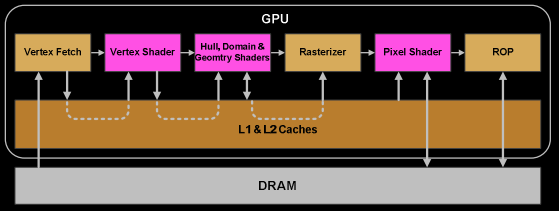
再详细介绍渲染流程之前,我们先简单了解(A)、(B)、(C)之间的关联:
- (A)是一个完整的渲染流程,包含了接受图形API命令、线程(组)调度、图形渲染流水线流程。
由(A)中的VS、GS、Viewport Transform组成的方块,以及由Attribute Setup、PS组成的方块在一个SM上运行,也就是(B)。
而(C)则是对(A)和(B)的抽象和概括。不仅仅显示了图形渲染流水线的关键步骤、还形象的表明了Vertex Shader的输出如何成为Rasterizer、Pixel Shader的输入等这些数据传递流程。(C)中的DRAM(Dynamic Random Access Memory)读写速度慢,集成度高,生产成本低,多用于容量较大的主存储器。
接下来,我们结合(A)、(B)、(C),介绍GPU的渲染流程,这部分有许多介绍,也大同小异,但比较容易理解,这里也基本是复述了一遍。
程序通过Graphics API(DirectX、OpenGL)发出draw call指令,指令会被推送到驱动程序,驱动程序会检查指令的合法性,然后会把指令放到GPU可以读取的Pushbuffer中;
经过一段时间或者显式刷新(调用flush指令)后,驱动程序把Pushbuffer的内容发送给GPU,GPU通过主机接口(Host Interface)接受这些命令,并通过前端(Front End)处理这些命令;
图元分配器(Primitive Distributor)根据index buffer中的顶点索引,生成三角形批次(batches),并分配给多个GPCs(图形处理簇);这里也就对应了图形渲染流水线最初的一步;
在GPC中,每个SM中的Poly Morph Engine(多边形引擎)通过三角形索引(triangle indices)取出三角形的顶点数据(vertex data),即图中的Vertex Fetch模块;
获取三角形顶点数据后,在SM中按照Warp(32个线程组成一个Warp,AMD为64个)来调度,处理顶点数据;这里也就涉及到了顶点着色器;
SM的Warp Scheduler会按照顺序分发指令给整个warp,单个warp中的线程会锁步(lock-step,一个Warp中线程同步执行)执行各自的指令,如果线程碰到不激活执行的情况也会被遮掩(be masked out);warp中的指令可以被一次完成,也可能经过多次调度,例如通常SM中的LD/ST(加载存取)单元数量明显少于基础数学操作单元由于某些指令比其他指令需要更长的时间才能完成,特别是内存加载,warp调度器可能会简单地切换到另一个没有内存等待的warp,这是GPU克服内存读取延迟的关键,只是简单地切换活动线程组。为了使这种切换非常快,调度器管理的所有warp在寄存器文件中都有自己的寄存器。这里就会有个矛盾产生,shader需要越多的寄存器,就会给warp留下越少的空间,就会产生越少的warp,这时候在碰到内存延迟的时候就会只是等待,而没有可以运行的warp可以切换;
一旦warp完成了vertex shader的所有指令,运算结果会被Viewport Transform模块处理,三角形会被裁剪然后准备栅格化,GPU会使用L1和L2缓存来进行vertex shader和pixel shader的数据通信;
接下来这些三角形将被分割,再分配给多个GPC,三角形的范围决定着它将被分配到哪个光栅引擎(Raster Engines),每个Raster Engines覆盖了多个屏幕上的tile,这等于把三角形的渲染分配到多个tile上面。也就是像素阶段就把按三角形划分变成了按显示的像素划分;
SM上的Attribute Setup保证了从vertex-shader来的数据经过插值后是pixel-shade是可读的;
GPC上的光栅引擎(raster engines)在它接收到的三角形上工作,来负责这些这些三角形的像素信息的生成(同时会处理Clipping、背面剔除和Early-Z剔除);
32个像素线程将被分成一组,或者说8个2x2的像素块,这是在像素着色器上面的最小工作单元,在这个像素线程内,如果没有被三角形覆盖就会被遮掩,SM中的warp调度器会管理像素着色器的任务;
接下来的阶段就和vertex-shader中的逻辑步骤完全一样,但是变成了在像素着色器线程中执行;这里涉及到统一着色器架构(Unified shader Architecture)的概念;
最后一步,像素着色器完成颜色计算和深度值的计算后,还必须考虑三角形的原始api顺序,然后才将数据移交给ROP(render output unit,渲染输入单元),一个ROP内部有很多ROP单元,在ROP单元中处理深度测试,和framebuffer的混合,深度和颜色的设置必须是原子操作,否则两个不同的三角形在同一个像素点就会有冲突和错误。
Computer Shader与GPU架构的对应关系
许多图形API会将渲染任务或计算任务分配到不同的SM或Core上,例如HLSL中的Dispatch、numthreads。他们对应GPU物理架构的不同层级。本节将首先介绍程序是如何在GPU上运行的,然后介绍HLSL中的语法与GPU物理架构的对应关系。
本节内容参考自:
从硬件上浅谈Compute Shader - 知乎 (zhihu.com)
【精选】GPU架构和Compute Shader线程规划_gpc tpc-CSDN博客
Compute Shader的并行性利用了Compute Units中的SIMD units(single instruction multiple data,单指令多数据)。为了使Computer Shader中的threads更高效的传输给SIMD进行处理,threads被组织成一个具有2个层级的数据结构(Compute Space)。
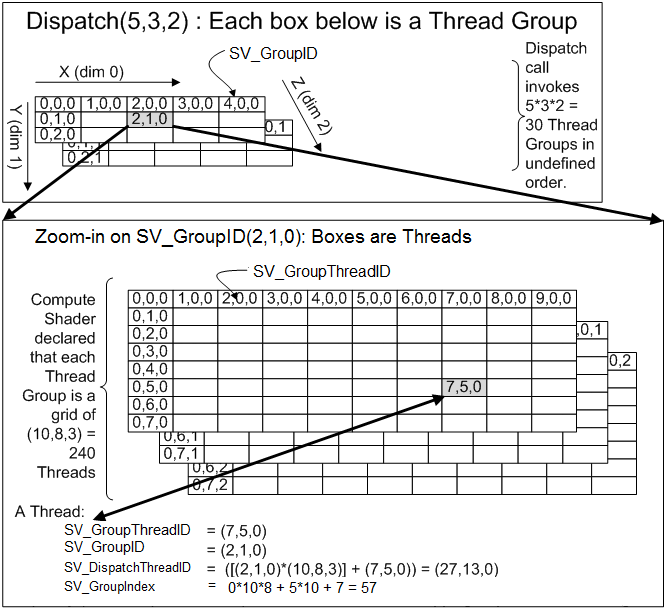
这里将其分为两个层级:work group和numthreads。
work group(higher level)
又称thread group。可以使用Dispatch(x,y,z)定义一个三维的thread group的组,每个组包含一个三维的numthreads。由于threadgroup的执行没有确定的顺序性,compute shader也就不可以依赖于特定的threadgroup执行顺序。
在C++语言中编写,指定线程组的组织。一个线程组运行在一个SM上。
根据DX12龙书的描述,每个SM至少应该拥有两个线程组,即线程组的数量应该为SM数量的2倍。这一设置为了保证处理的并行性,使得每个SM至少被分派了两个线程组,当SM正在执行的一个线程组处于等待的状态时(比如等待纹理的处理结果),SM可以切换到另一个线程组执行。
numthreads (lower level)
又称local size。[numthreads(x,y,z)]定义每个threadgroup的大小。例如如果numthreads定义了(8,8,1),Dispatch(4,4,1)大小的work group,那么整个thread count为1024. 值得注意的是threadgroup内的每个thread是并行处理,并可以通过一些共有的变量交换数据。而threadgroup之间无法高效的沟通。
在HLSL语言中编写,指定线程组中线程的组织。线程被分派给SM中的每个Core(或称SP)。线程组中的线程数一般设置为Core数量的整数倍,对于Nvidia显卡来说应当是32的整数倍,而对于AMD则应该是64的整数倍。
这里值得注意理解一种情况,例如,对于一个有32个Core的SM,若给它分配的一个线程组含有64个线程,这些线程将如何执行。这里边涉及到了Wrap的概念,一个Wrap包含32个线程。线程组以Wrap为单位执行,Wrap Scheduler切换Wrap执行。指令调度单元(Instruction Dispatch Unit)从指令缓存中取出shader中的操作指令,分配给每个Core去执行。调度单元分配给每一个Core的指令都是相同的,但每个Core操作的数据是不同的,这就是所谓的SIMT(单指令多线程)。
因此,对于D3D平台上的Computer Shader编程,涉及两部分的调度。一是对线程组的调度(线程组调度器),二是对Wrap的调度(Wrap调度器)。对线程组的设计(x、y、z的取值)在C++中完成;对每个线程组的设计则在HLSL中完成。因此,在HLSL语言中编写的每个函数,实际上是针对每个SM中的一个Wrap编写的。